|
Fazli Imam Hi, I’m an AI Researcher (Level II) at MBZUAI, supervised by Dr. Alham Fikri Aji at MBZUAI, focusing on exciting challenges in multimodality and visual temporal reasoning capabilities of vision-language models. Previously, I earned my master’s degree in machine learning from MBZUAI where I was supervised by Dr. Hisham Cholakkal. Before venturing into academic research, I honed my skills as a Data Scientist at Stax Inc.. and at NICST, where I applied data-driven insights to solve complex use cases. I'm currently seeking Data Science and Machine Learning job opportunities. Feel free to reach out if you have any questions or would like to know more. |

|
News
- Aug 2024: Joined Dr. Alham's lab at MBZUAI as an AI Researcher
- July 2024: Team mentored by our lab wins "Best Team Award" at MBZUAI Undergraduate Research Internship Program
- June 2024: Graduated with MSc in Machine Learning from Mohamed Bin Zayed University of Artificial Intelligence
- July 2023: Short stint at ADNOC's Panorama Digital Command Center
- Aug 2021: Started MSc in Machine Learning at Mohamed Bin Zayed University of Artificial Intelligence
Research
|
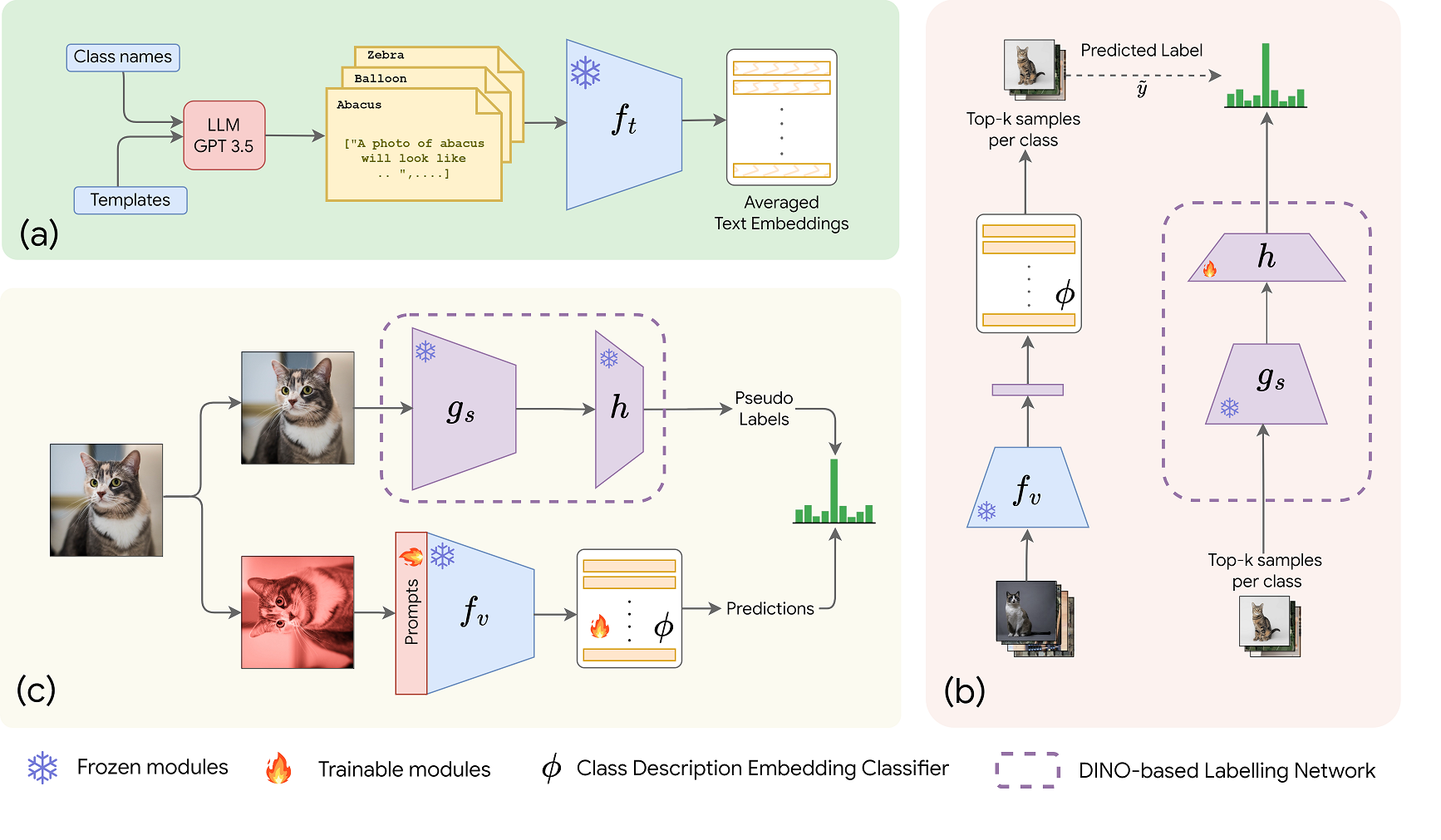
CLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Mohamed Fazli Imam, Rufael Fedaku Marew, Jameel Hassan, Mustansar Fiaz, Alham Fikri Aji, Hisham Cholakkal arXiv / code We propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabelled images. |
|
Can Multimodal LLMs do Visual Temporal Understanding and Reasoning? The answer is No!
Mohamed Fazli Imam, Chenyang Lyu, Alham Fikri Aji arXiv / dataset We proposed TemporalVQA,a benchmark to evaluate the temporal reasoning capabilities of Multimodal Large Language Models (MLLMs) in tasks requiring visual temporal understanding. |
|
Encoder-only Models are Efficient Crosslingual Generalizers
Ahmed Elshabrawy, Thanh-Nhi Nguyen, Yeeun Kang, Lihan Feng, Annant Jain, Faadil A. Shaikh, Jonibek Mansurov, Mohamed Fazli Imam, Jesus-German Ortiz-Barajas, Rendi Chevi, Alham Fikri Aji ACL ARR Submission, 2024 We extend Statement Tuning to multilingual NLP tasks, investigating whether encoder models can achieve zero-shot cross-lingual generalization and serve as efficient alternatives to memory-intensive LLMs for low-resource languages |

|
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
David Romero, Chenyang Lyu∗, Haryo Akbarianto Wibowo, Thamar Solorio Alham Fikri Aji, 71 more authors , NeurIPS Dataset Track, 2024 arXiv / project page A Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. |
|
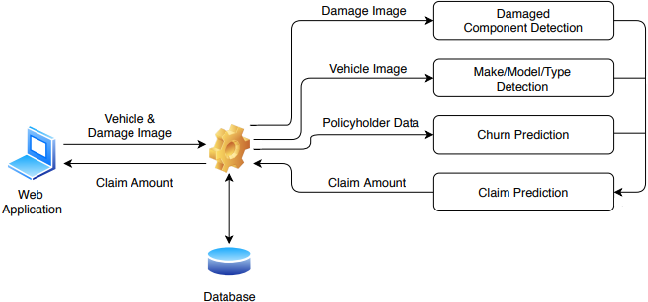
Moderate Automobile Accident Claim Process Automation Using Machine Learning
Mohamed Fazli Imam, Achinthya Subasinghe, Hiruni Kasthuriarachchi, Senura Fernando, Nadeesa Pemadasa, Prasanna Haddela 2021 International conference on computer communication and informatics (ICCCI), 2021 paper We introduce a computer vision and machine learning-based system to automate the processing of minor automobile accident claims, incorporating damage assessment, repair cost estimation, and policyholder churn prediction to improve efficiency and retention outcomes. |
Experience

|
AI Researcher (Level II) July 2023 - Present |

|
Fellow June 2023 - July 2023 |

|
Data Scientist July 2021 - July 2022 |

|
Data Scientist Nov 2020 - June 2021 |
Education
|
|
Mohamed Bin Zayed University of Artificial Intelligence, Abu Dhabi, United Arab Emirates
MSc. in Machine Learning
Aug 2022 - June 2024
|
|
|
Sri Lanka Institute of Information Technology (SLIIT), Malabe, Sri Lanka
Bachelor's in Science (Hons) in Information Technology Specializing in Data Science
Jan 2016 - Dec 2020
|